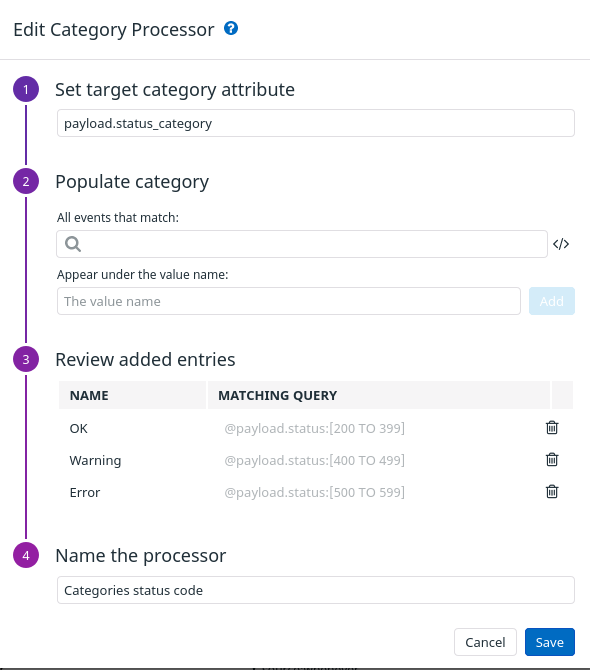
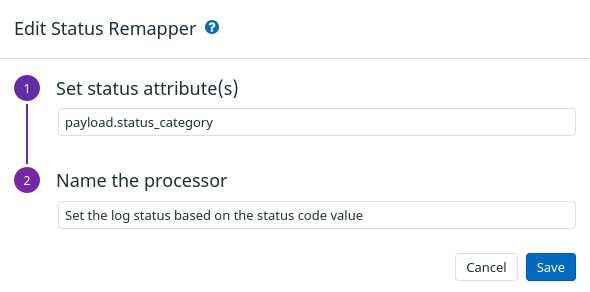
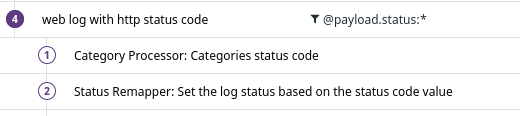
初めてのGitHub Actionsの開発。
Actions開発の背景
タスク管理にGitHub issueではなくRedmine issueを利用しているのだけれど、プルリクを作成したときにRedmine issueへのリンクを記載することがよくある。 git コミットにissue番号を記載して連携させれる方法もあるけど、コミットレベルではなくプルリクレベルで連携させたかった。
あまりこういった取り組みは行われていないようなので、GitHub Actionsでプルリクの内容を解析してリンク先のRedmine issueにコメントを残すActionを開発した。 これによってGitHub側の開発状況がRedmineにコメントとして自動反映されるので、わざわざRedmine issueを手動で更新しなくて済むようにした。
開発の取り組み
GitHub Actionsについて
基本的には公式ドキュメントの アクションの開発を読み進めていった。
最初は環境変数を通して必要な情報が渡されないかなと期待したけど、欲しい情報はなかったのでしっかりと作り込むことにした。 Actionを開発する上で、JavaScriptに慣れておらずDockerに慣れていることから、Dockerアクションで実装しようかと思っていた。ただし、RedmineのAPI叩くためだけにDockerイメージのプルするのはやり過ぎかなと思ったのと、DockerアクションはJavaScriptアクションより遅いとうことだったので、JavaScriptアクションで実装してみることにした。JavaScriptを使う良い機会とも思ったので。 ただし、プルリクを作成したタイミングでしか実行されず、コメント通知が少し速くてもまったく嬉しくないので、JavaScriptアクションを選択した意味はあまりなかったかもしれない。
Action開発する上では、どのようにGitHubから必要な情報を取得するかが悩みどころだった。パッケージとしてはtoolkitが公開されているけど、細分化されておりどのパッケージが必要なものかわからなかった。 結局はGitHub Actionsに関する情報取得は @actions/coreを、プルリクに関する情報は @actions/githubを利用した。ただし、@actions/github を使う上で欲しい情報がどのように取得できるかは最後までよくわからなかった。一応 ドキュメントはしっかりあるけど、各APIを叩くと具体的にどのような情報が取得できるのか判断できなかった。結局は実際にAPIをいくつか叩いてみたりしてあたりをつけた。
Node.js アプリ開発
Node.jsアプリ開発はほとんど経験がなかったので、結構基本的なところから試行錯誤していたので思ったより時間を掛けてしまった。 基本的には javascript-action-templateの通り。 迷ったのは以下の通り。
パッケージマネージャとしてのnpmについて。 てっきりyarnを利用するのかと思ったけど、サンプルにはnpmしかなかったので、そのままnpmを利用し続けた。yarnの方が良いらしいくらいにしか理解していないのと、npmで困っていないので現状もnpmのまま。
パッケージの配置について。 動作検証として開発中のActionsをGitHub上で動かしてみたけど、node_modulesが見付からないというエラーで動作しなかった。原因は全部ドキュメントに書いてあるのだけれど node_modulesごとコミットする必要があるとこのと。 ただし、他のプロジェクトを見てもnode_modulesをコミットしているプロジェクトはほとんど見あたらず、テンプレートすらnode_modulesをコミットする方針は採用していなかった。また、コミットするにしてもmainブランチにはコミットせずリリースブランチ/タグでのみコミットしないと開発がやりずらくなる、みたいな情報もあった。node_modulesの中身もきちんと理解していないのでコミットしたくないという思いもあり、テンプレートは他のActionsと同じように@vercel/nccを利用する方針を採用した。 ただし、nccをどのように実行すればよいか解決していない。現状はアプリを修正したときやパッケージを更新したときに手動でコマンドを叩いている。リリースプロセスの中で自動実行する仕組みにしないと間違えそうだなという不安が残っている。
テストについて。 node.jsのテストフレームワークとしてjestは前々から使ってみたいなという思いはあったので喜んで採用した。単体テスト自体は慣れているし、違和感なくテストを書くことができた。 ただしテストを書くためには対象関数を別ファイルに分割する必要があったり、テストのためだけに? module.exportsしたりと、本当にこのやり方でいいのかなという違和感が残っている。 Redmine APIもよくわからない事が多いので、できればRedmine APIをモックにしてテストを書きたい気持ちもあったけど、そこは面倒そうなので諦め。
Redmine API用のライブラリについて。 探すと node-redmineがあったので特に悩まず採用した。実際問題なく開発を進めることはできた。 ただし、後から確認してみるとまったくメンテされておらず、開発者もその気がなさそう。今後の事を考えると別のライブラリ(例えば axios-redmineなど)を採用しておけばよかったかもしれない。
TypeScriptについて。 TypeScriptでの開発はまったく検討していなかったけど、開発中の調査等でTypeScriptという選択肢があることに気が付いた。また、TypeScriptのテンプレートも用意されている。 TypeScriptもどこかで使ってみたいという思いはあるけれど、まあ別の機会ということでスルーした。
アプリの実装について。 あまり複雑な処理はないが、唯一困ったのがプルリクの本文からRedmine issueへのリンクを取得する部分。特にissue番号の一覧だけが欲しいのをどうするかが悩みどころで結構時間を使ってしまった。 結局は RegExp.exec を使えばシンプルに実装できるとわかり無事解決。
リリース
リリースをどうするかはまだ解決していない。 特に利用において、現状では @main のようにメインブランチを指定する利用方法を想定しているが、できればよくある@v1のようなバージョン指定をサーポートしたい。しかし、これを実現するにはv1タグをリリースの度に打ち直す必要がある。できればタグは一度打ったら別のコミットに打ち直したくないので、このリリース方法には違和感がある。 解決策としてv1ブランチを作成することにした。これで@v1.0.0 指定と@v1指定の両方がサポートされ、v1タグをリリースの度に打ち直す必要はない。ただし、v1.0のようなマイナーバージョンまでの指定はサポートできない。最新機能に追従するv1指定か、バージョンを固定するv1.0.0指定の2つがサポートされていればまずはOKだろうか。
今後の展望
まだまだやりたい事はたくさんあるがどこまで対応できるか不明。しばらく使ってみてから考える。
機能としては、Redmineのissueステータス更新やメッセージのカスタマイズなんかはやりたい。 非機能としても、リリースプロセスは整備したいし、テストまわりももう少しきちんと書きたい。あとはREADMEもえいやで書いたので英文を見直したい。
それ以外にも、だいたい実装が完了した時点で、GitHub Actions実践入門の書籍にActions開発についても触れられていることを知った。てっきりActions利用のみだと勘違いしていた。Actions開発については分量はそこまで多くないし、Actions側のアップデートもあるので全部そのままは利用できないかもしれないが、今回自分がActionsまわりで悩んだ点くらいは楽に解決できたかもしれない。
)")

")