まさか2024年のふりかえりの記事の次が2025年のふりかえり記事になるとは。
2025年のふりかえり
したこと
自宅サーバ環境の整備
もともと懸念だった自宅サーバ環境の整備に取り組んだ。 HWまわりの整備(NAS追加、2.5GbEネットワーク設置、ミニPC設置)、IaaSまわりの整備(Proxmox VEクラスタ、DNS+DHCPサーバ)、k8sクラスタの構築など。
自宅サーバ環境は、AWSを使うようになってわざわざ自宅環境を整備するモチベーションが減少して放置していた。もともとはSaaSが使えない環境での検証用途として、GitLabやJenkinsなどを構築・検証するための基盤として利用していた。これがGitHubなどのSaaSが利用できるようになり、検証環境も不要になったので自宅検証環境が不要になった。
この事情がk8sを業務で利用するようになって一変し、自分用のk8s検証環境が必要になった。k8s自体の理解度を上げる必要があるし、k8s上で実行するアプリケーション運用の経験も積む必要がある。とはいえ自分の個人検証用途にk8sクラスタをGKE等で構築運用するのはかなりお金が掛かる。検証期間だけ構築するにしてもセットアップに時間は掛かるし、運用検証ができないのが課題だった。
これを解決するために自宅k8sクラスタを構築した。Googleがカスタマイズしていないバニラなk8sが欲しいし、k8sやその上で動作するアプリケーション群を自分で検証したい。このためにはある程度リッチな環境が必要と判断した。 もちろん、ラズパイのようなシングルボードコンピュータを用いて簡易クラスタを組むのも手だが、ミニPCであれば消費電力的にもスペック的にも十分だし望ましいと判断した。
現状でも無事にクラスタが稼動して無事に検証に活用できている。 バージョンアップグレードや監視まわりの整備などまだまだ足りていないところも多いが、それも含めて2025年中に一応整備できてよかった。
Webサービス開発への着手
生成AIを活用していろいろ試せるようになったことで、自分向けのサービス開発が進んだ。
これまではフロントエンドまわりに苦手意識があり着手できなかったアイデアも、生成AIの支援により形にできるようになった。技術検証のMVPとしてのプロダクトづくり
また、前述の自宅k8sクラスタを構築したことで、とりあえずそこにデプロイして利用するという選択肢が生まれたのもサービス開発が進む1要因となった。業務でGoogle Cloudのナレッジが蓄積できて、ゼロスケールの環境としてCloud Run Serviceも選択肢に生まれたのもよかった。 従来はVercelなどが選択肢としてはあるものの、制約も多かったり、結局DBどこに立てて運用するの(お金掛けるの)という疑問が解消されなかった。ECSを使うとコンピューティングリソースのお金が掛かるのも制約だった。
一方で、結局最後までリリースできたサービスはおそらくなさそう? どれも中途半端に手を掛けてそのまま放置で終わっている。これがよろしくない。
自分に足りないものの認識
これをしたこと、に含めるのは若干違和感があるが。 転職から1年が経ち、やっと自分に何が足りないのかわかってきた。転職直後の何もかも足りないという感覚から、これは通用する、これは無くてもまだ何とかなる、これは明確に足を引っぱっている、といったグラデーションが見えてきた。
具体的にはソフトスキルとSREとしての専門性が課題に感じている。
1つ目はソフトスキルは、特に他人にわかりやすく伝える能力が足りていない。 頭の中では課題感を描けていても、これを言語や文章で相手に伝え、行動変容を引き出すことができていないでいる。特に相手の専門性が異なると顕著。 これはSREとしてエネーブリング力が特に求められるので致命的になっている。現在は相手が寄り添ってくれたり、他のSREにサポートしてもらってなんとかなっているがこれを改善する必要がある。
2つ目はSREとしての専門性が足りていない。もともとは、IaCに強みを持つと認識しており、また幅広い技術領域に一定の知見があるのでどのような技術的課題にも対処できることろは強みがあると思っていた。実際、これについてはある程度通用することがわかりなんとかなった。
一方で、IaCの強みを発揮するには対象のプラットフォームについての知見、具体的にはGoogle CloudやCloudflareなどの理解も必要で強みを発揮しずらい状況にある。この状況でIaC(terraform)の専門性を強化しても自身の価値向上としては効果が薄かった。 IaCに並ぶ別の強みや専門性を獲得する必要がある。とはいっても従来持っていたVM層の知見は今は何の価値もないので、SRE領域で専門性を磨いていきたい。隣接するDev/OpsやPlatform Engineeringも含めて専門性を獲得することも、現在の知識の幅という意味での強みを伸ばすことにはつながるが、そうではなくSREとしてSREの専門性を強化したい。 具体的にはSLI/SLO、オブザーバビリティ、アラート/モニタリング、インシデントレスポンス、キャパシティプランニングなど。
できなかったこと
2025年の目標
2025年の目標として掲げた「1つ1つ学ぶ」「データと仲良くなる」「強みを伸ばす」にはほとんど取り組めなかった。目標設定が自分に足りないものとズレていて、この目標に合った行動を取れなかった。 本来は目標をすぐに修正して取り組むべきだったが、目標修正というアクションを取れずにずるずると過ごしてしまった。 これは目標設定が若干形骸化していた面もある。自分が今後どのように成長すべきかキャリアの迷子感が出ており(だからこそ転職したという面もある)、具体的に何をすればよいかわかっていなかった。
この1年掛けて自分に足りないこと、やりたい事がより明確になったので新しい目標を定めて取り組みたい。少なくとも、目標が変わったら修正できるようにしたい。
インプット/アウトプットの減少
インプット/アウトプットは質・量ともに減少した1年だったなと感じる。
インプットについて、読んだ書籍も少ないし、勉強会に参加する頻度も減った(オンラインですら参加しなくなった)。ポッドキャストやブログなんかのインプットもだいぶ減った気がする。 ここは適量となる定量的な閾値は存在しないので感覚的なものになるが、少なくともこの1年はどれも足りていない印象。 別に数を計測する必要はないけれど、意識して情報を取り入れていく。
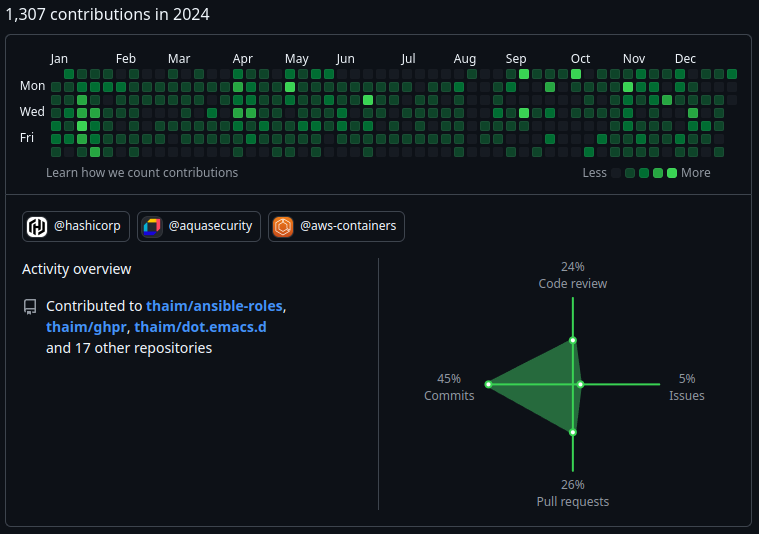
インプット以上に深刻なのがアウトプットの低下。 ブログ記事はメインブログが1件、サブブログが10件、Zennが3件で合計14件だった。また、ソフトウェアとしてもリリースできたといえるものが挙げられない。これはアウトプットとしてはだいぶ少ない。
「1つ1つ学ぶ」という2025年の目標においても、学んだことをアウトプットしたかったができなかった。 これは、時間確保の問題とアウトプット対象となる課題選定に問題があると感じている。
- 生活の質低下による時間不足
- 睡眠の質が悪く、生活が崩れがちだった
- 業務で疲れてプライベートでの研鑽の時間を確保できなかった
- 時間の使い方が下手でメリハリをつけられなかった
- 取り組む技術課題のミスマッチ
- 業務と関連性の高い課題、低い課題の混在
- やりかけタスク増に伴うフロー効率の低下
時間確保不足については、生活の質が低下したと実感しておりその影響かと感じる。 単に机に向かう時間が確保できていない。ぐったりしている、だらだらしている時間が多い。休むなら休むべきだし、取り組むなら集中するべきだった。 これはもう睡眠の質が一番の原因であることがわかっているのでこれの改善は引き続き行っていく。 年齢からくるやつだから、ある程度はしょうがないにしてもできるだけ改善したい。
一方で費やした時間も無駄(?)なことに掛けてしまった実感がある。 これは生成AIのおかげで今までできなかったことができるようになったので、いろいろ手を伸ばし過ぎた印象。せめてその成果をきちんとアウトプットにまとめることができたらよかったのだけど、それもできなかった。 どうしても作業が並列化しがちで、その結果ある程度まで成果が出たら次のタスクを着手してしまい、結果やりかけのプロジェクトが多数できてしまった。中にはいつかはやりたいな、みたいな実験的なプロジェクトも含まれており、それはそれでいいのだけれど今やるべきことではなかった。 もっと重要度・緊急度に合わせた作業優先度レーンを意識して、優先度が高いものを最後までやり切る、優先度が低いものは空いた時間で対応できるようにしたい。
その他
技術以外に使った時間としては、zwiftと雀魂がある。
zwiftは1年で 167時間 / 4209.9km だった(バーチャルライド以外も多少含まれている)。これは2024年の 231時間 / 5783.1km に比べるとだいぶ減少している。その実感はあり、全然走れていない。 時間と強度の両面でもっと取り組みたい。継続した運動は今後の生活の質向上および体力維持に必要不可欠なので、もうひと頑張りしたい。 レースへの参加もグループライドへの参加も減っているのでこれらの継続が必要。
雀魂は1年で682局打った。ちょっと打ち過ぎでは? 1日1半荘を目標に、豪3から傑3まで行ったりきたりで現在は豪1で停滞している。 2024年ごろから打つようになり、覚えることたくさんで楽しく打てていた。モチベーション的にもひと段落した感があり、2026年はもう少し見直すかも。
2026年の抱負
ソフトスキルの改善
業務上でも一番の課題となっており、ここにプライベートでも時間を掛けたい。
対人スキルについては業務を通して学ぶことが大半かもしれないが、プライベートでも学ぶべきことはたくさんありそう。 具体的には、スタッフエンジニアリングの文脈でのリーダーシップ、ドキュメントライティングの文脈での文書作成術、アジャイル文脈でのコラボレーションなど。これらのインプットについては力を入れたい。
また、ブログ執筆という形で実践したい。短い時間でわかりやすく伝えるという意味ではブログ記事の作成はまさに実践的なテーマ。 1つ1つの記事に時間を掛け過ぎずにわかりやすい記事を書けるようになりたい。
SREに関する専門性の獲得
IaCだけでなく、それに並ぶ専門性を獲得する。具体的な領域はまだ定まっていないので目標としては弱いが、基本的にはどれか1つしか身に付けないのではなく、SREとしてのスキルの底上げとして全体的に伸ばしながら特定の領域で強みを発揮できるようにしたい。 現状ではSLI/SLO、オブザーバビリティ、アラート/モニタリング、インシデントレスポンス、キャパシティプランニングなどが候補だが 専門技術として学ぶ余地が大きいという意味ではオブザーバビリティにはぜひ取り組んでみたい。
時間の使い方の改善
技術的なテーマではないが、影響が大きいので意識して取り組みたい。 睡眠の質を改善し、生活リズムを改善する。メリハリをつけた時間の使い方を意識して、集中した時間を確保できるようにする。
睡眠と生活リズムは、運動・食事・睡眠の取り組み改善を継続する必要があると思うのでこれを意識する。
時間の使い方について、現状だとポモドーロぐらいしか仕組みによる改善方法が無い。 ポモドーロの利用は継続しつつ、それ以外の選択肢や仕組みを取り入れてみたり、作業時間以外の時間の使い方を意識できるようにしたい。
 Porcelain GA04750-JP")


![LeanとDevOpsの科学[Accelerate] テクノロジーの戦略的活用が組織変革を加速する impress top gearシリーズ](https://m.media-amazon.com/images/I/51TuqLnPBCL._SL500_.jpg "LeanとDevOpsの科学[Accelerate] テクノロジーの戦略的活用が組織変革を加速する impress top gearシリーズ")



